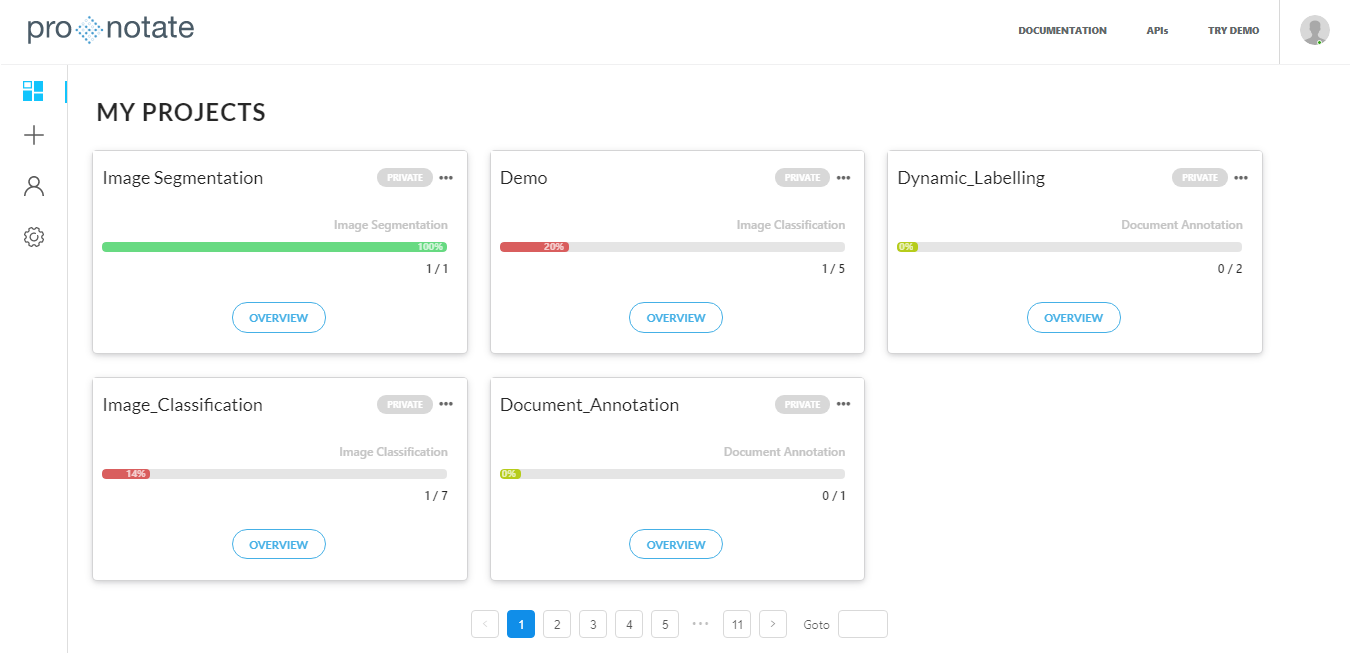
Introducing ProNotate - A Cutting-Edge Data Labeling Platform for AI.
We are excited to announce our latest launch – ProNotate, a web-based and collaborative data labeling platform for enterprises. ProNotate enables enterprises to meet industry requirements in training expert machine learning applications.
With a distinctive and user-friendly interface, ProNotate makes it easy to annotate and label many different data types (such as image, text, and video) to build efficient and accurate training datasets. With ProNotate, users can add to or edit datasets at any point in time, add members to projects to collaborate, visually evaluate their annotated dataset, and create dynamic labels.
ProNotate supports both on-premise data and hosted data. Our team built ProNotate with cutting edge technologies including MySQL, Java, Hibernate, React with Redux, ANT & Semantic UI, DropWizard Framework, Docker, and AWS.
Types of Annotations
1. IMAGE ANNOTATION
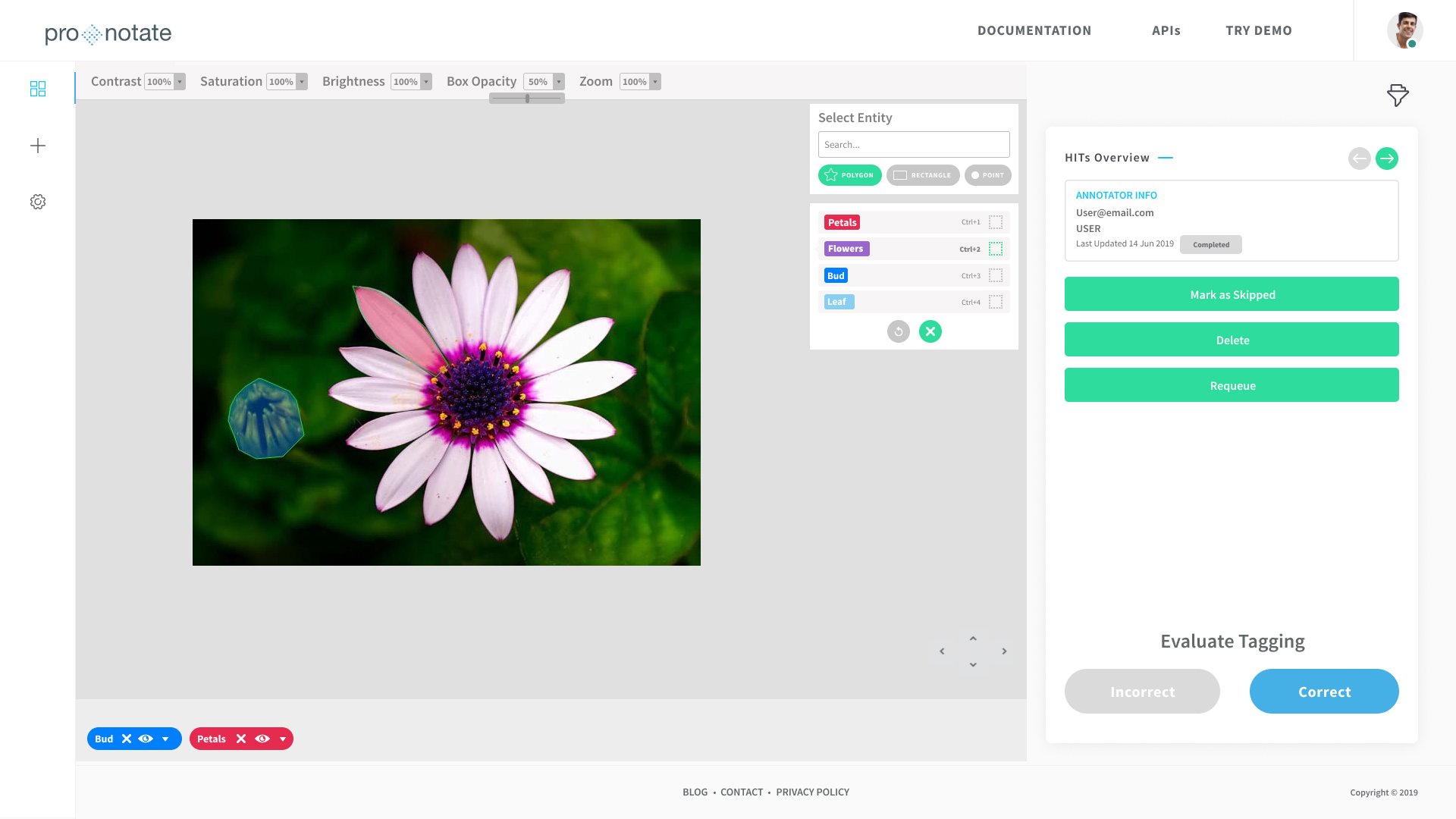
ProNotate supports three types of image annotations namely image classification, image segmentation, and image bounding box. The user can tag any number of entities or labels for each annotation, and the output can be exported in the JSON format.
Image Classification allows multi-class classification of images, based on certain criteria. For example, a user could classify images based on brands. The sample dataset can be uploaded as a text file with multiple image URLs/individual images/a tsv file/a zip file of all images/pre-annotated JSON file.
Image Segmentation lets the user annotate different portions of an image with multiple labels, using inbuilt tools like Polygon, Rectangle, and Point.
Image Bounding Box allows the user to draw rectangles around objects in an image and label them to a class.
Image segmentation and bounding box allow input files in any image file formats, a text file with multiple image URLs, a zip file of all images or a pre-annotated file in JSON format.
2. VIDEO ANNOTATION
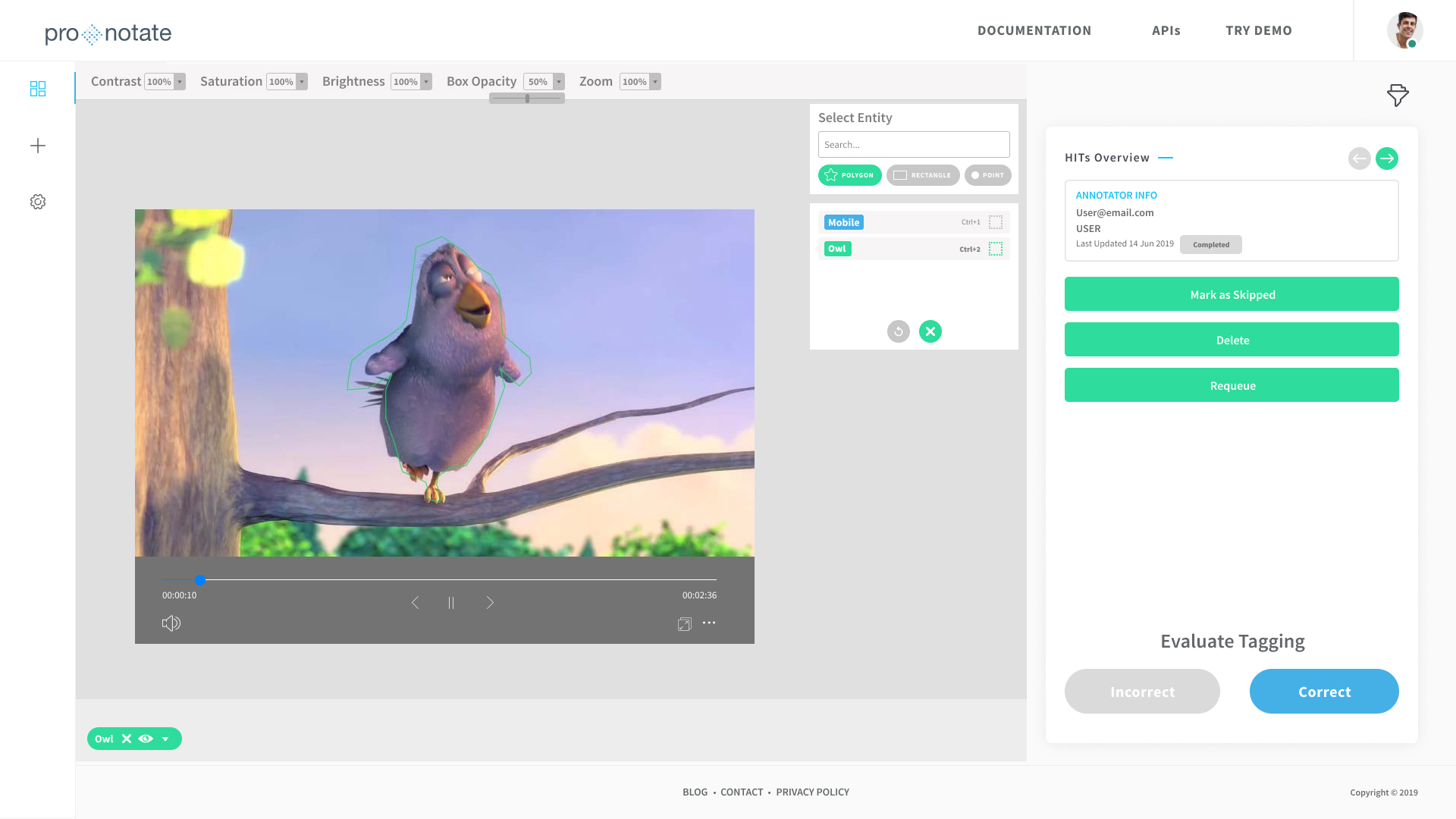
Our video annotation platform provides high-quality data annotations that not only look accurate to the human eye but also effectively train machine learning algorithms. The video URLs can be uploaded individually or as a zip file, to create a sample dataset for video annotation projects, and the annotation can be exported in JSON format. A pre-annotated dataset can also be uploaded to the platform.
Video Classification is used to classify videos based on predefined categories. ProNotate allows a user to select multiple categories or classes for each video.
Video Analysis & Annotation is a feature that determines the static and temporal objects in a video and annotates them using bounding boxes and polygons.
Object/Motion Tracking tracks moving objects in a video by interpolation of bounding boxes and keyframes, and automatic annotation.
TYPES OF VIDEO ANNOTATION
Video Classification
Like images, video datasets can also be classified using video classification.
Video Annotation
ProNotate uses a power-packed tool to perform object tracking in videos. The user draws a bounding box around a moving object and ProNotate performs a linear interpolation between the frames automatically, thus saving the user a tremendous amount of time. For a simple one-minute video, our process can reduce the annotation time from 30 minutes to 5 minutes, providing 6 times the improvement in efficiency while keeping the quality intact.
After annotating a video, the user can download the output as a JSON file. This JSON contains the coordinates of the bounding box at various time points in the video for each tracked object, along with additional metadata.
3. TEXT ANNOTATION
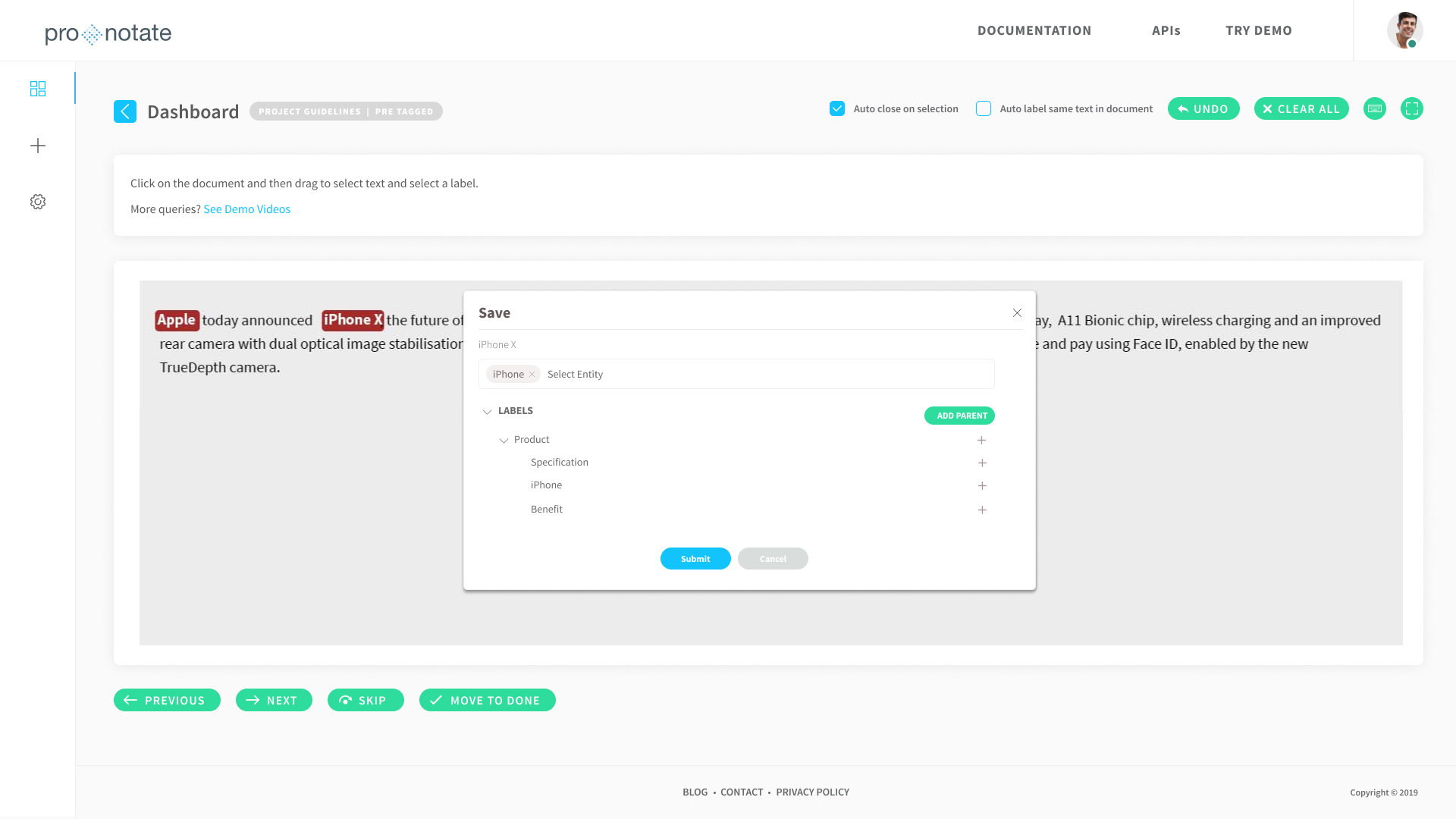
ProNotate is extremely flexible and supports input text files of any format (txt, csv, pdf, etc). Depending on the type of annotation the user chooses, ProNotate can divide a text file into data items on the basis of word, line, or document. ProNotate then intuitively displays each data item for the user to label one at a time.
Types of Text Annotation
1. Document Annotation
2. Named Entity Recognition Tagging
3. Part of Speech Tagging for small sentences
4. Text Summarization
5. Text Classification
6. Text Moderation
Document Annotation
With ProNotate’s Document Annotation, users can tag texts using a parent and child hierarchy. Users can input the dataset as an individual text/doc/pdf file, or as a zip file of text/doc/pdf, or even as a pre-annotated text file in JSON format. ProNotate exports the annotated files in JSON or Stanford NER format.
Based on a user’s specific project requirements they can create a dataset using two types of labeling:
1. Basic Label: used to define entities with no parent and no child
2. Advanced Label: used for projects with a Parent-Child label hierarchy. A user can add as many child labels as they wish to any parent entity.
Named Entity Recognition (NER) Tagging
Named Entity Recognition is a process by which an algorithm takes a string of text (a sentence or a paragraph) as input and identifies relevant nouns that are mentioned in that string.
Named Entity Recognition is the best NLP technique to use when a user wants the categorized data to be well-structured. For example, NER tagging can automatically generate a summary of a resume by extracting entities such as name, educational background, and past work experience.
Our team used Python’s spaCy module to train ProNotate’s NER model. spaCy’s models make decisions (such as which part of speech a word is) based on statistical predictions. This prediction is based on the examples the model has seen during training.
ProNotate allows users to upload text content in a text/csv/JSON file, and formats it’s NER Tagging output as either a text file (Stanford NER format) or a complete JSON.
Part Of Speech (POS) Tagging for small sentences
Part of Speech tagging captures the syntactic relations between different words in a sentence and is essential for building parse trees and lemmatizers. This tagging technique has a variety of applications such as sentiment analysis, answering questions, and word sense disambiguation. This feature allows the user to upload dataset in text/doc/pdf/JSON file formats, and the output can be exported in JSON or Stanford NER formats.
Text Summarization
ProNotate’s machine learning model can be trained to create a short, accurate, and fluent summary of any long text document.
Text Classification
Our text classification feature enables smart classification of text into categories.
Text Moderation
ProNotate’s text moderation helps to ensure that offensive, undesirable, confidential, and risky content are flagged in a text. A user can approve or review content based on a given project’s requirement. Moderation can flag for the following information:
1. Profanity: term-based matching with a list of profane terms in various languages
2. Classification: machine-assisted classification into custom categories
3. Personal data
4. Auto-corrected text
5. Original text
6. Language
For text classification, text moderation, and text summarization processes input files can be uploaded as a text file and the output can be downloaded as a text file in JSON format.