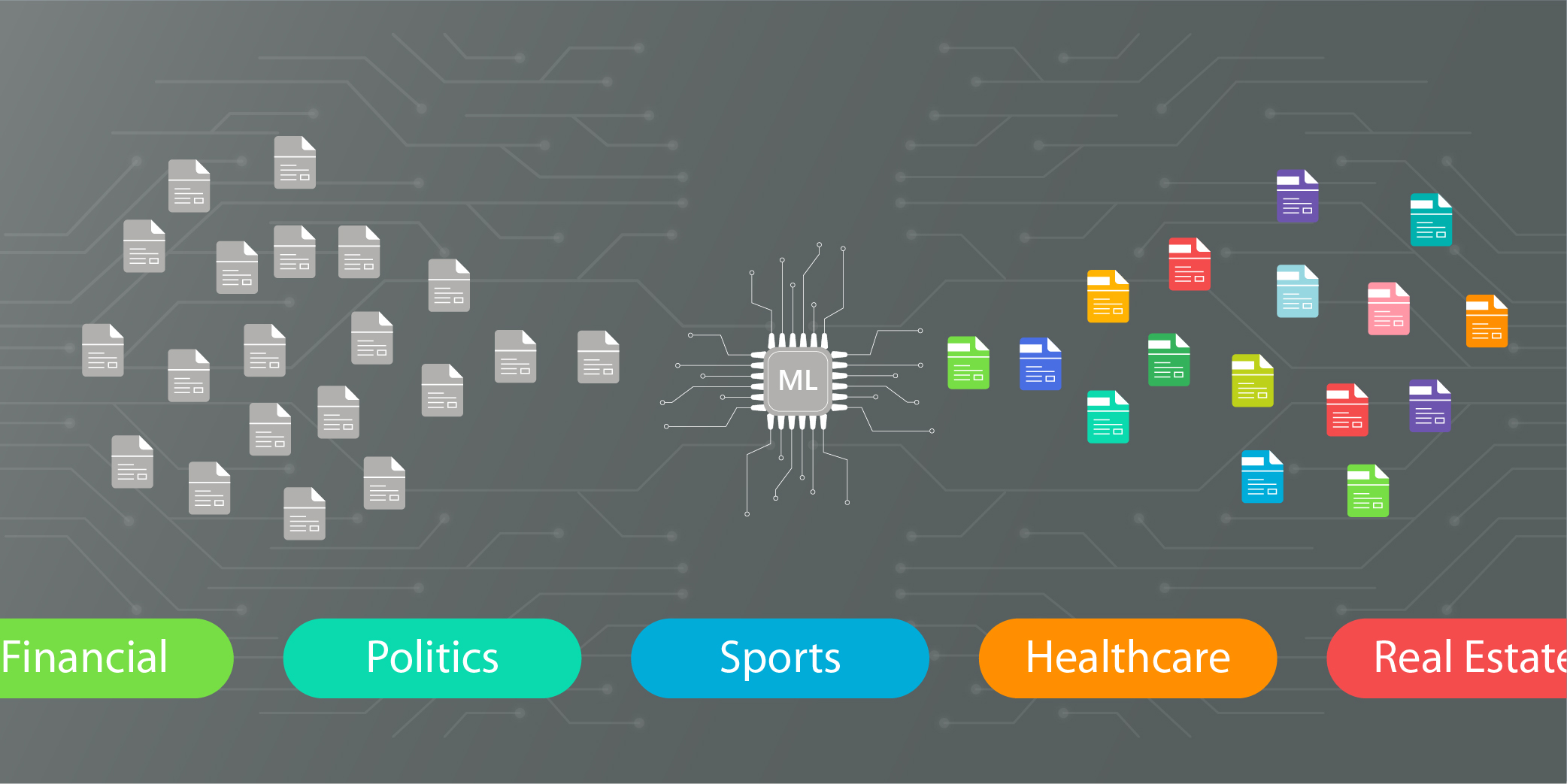
Classify Thousands of News Articles at the Click of a Button.
Most in the media monitoring sector are familiar with the idea that extracting insights from unstructured texts can be an incredibly tedious job. Luckily, text classification software can simplify the job for human analysts, saving them valuable time, and leading to more accurate results overall.
Our core Machine Learning team recently used TensorFlow to create a text classification model for one of our media monitoring customers. The software we created auto-tags and organizes news articles based on their descriptions, and saves human media analysts countless hours.
We created our Machine Learning model in Python and used Deep Convolutional Neural Networks. Our model was trained to predict the category of any new news article using pre-labeled article samples as training data.
WHAT IS TEXT CLASSIFICATION?
Text classification is the process of assigning a set of predefined categories to free-text. Text classifiers help in organizing, structuring, and classifying text of any kind, be it a set of new articles that needs to be organized by categories, customer support tickets that need to be sorted by urgency, or chat conversations to be grouped by language.
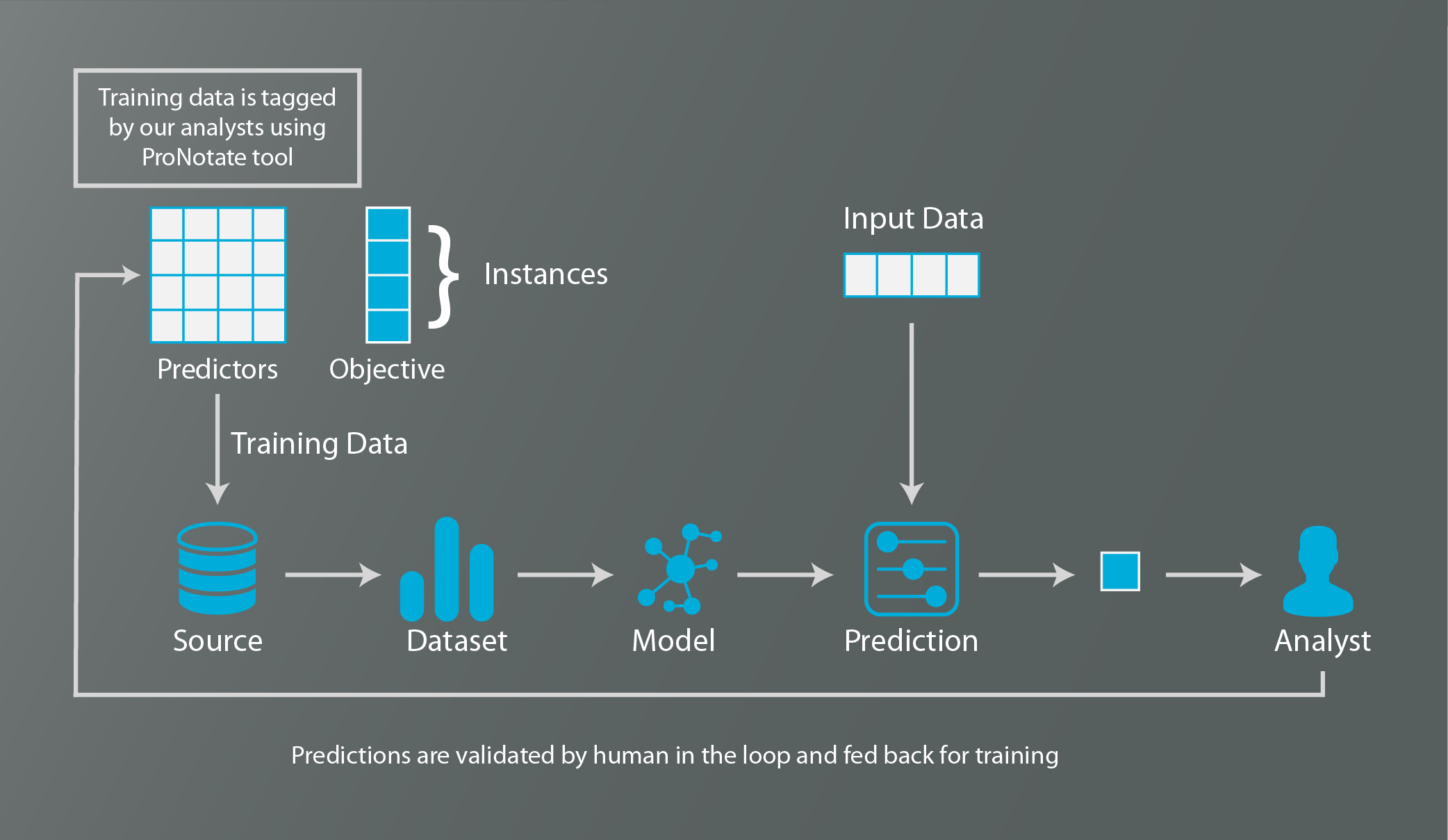
Training data
Training data is a set of sample data fed to a machine-learning algorithm to teach it what to look for.
Training data is often formatted as data with inputs and their expected outputs. For example, in an algorithm to categorize the sentiment expressed by a tweet, each input tweet in the training data would be labelled with the output sentiment it expresses. When the algorithm is training, it uses these inputs and their corresponding labelled outputs to recognize patterns. When we later input real data without an associated output, the algorithm uses the patterns it detected from the training data to calculate the output of the real data.
To create training data sets for our model, we used ProNotate, our in-house, web-based collaborative data labeling platform. ProNotate allowed us to quickly label text to create the most accurate training data possible.
Data Preprocessing
Before inputting any data to our model, we processed it to remove extraneous information. Our team carefully removed information such as HTML tags, special characters, and stop words (words which appear in text but do not hold much value) from the articles to be analyzed. Another component of this preprocessing was lemmatization, a procedure which groups together inflected forms of a word so they can be analyzed as a single item.
Feature extraction
The first step towards training a text classifier for Natural Language Processing (NLP) is feature extraction or vectorization. This method transforms text into a numerical representation in the form of a vector. We used the Bag of Words simplification model to represent the words in a given text.
Bag of Words
There are several ways to implement the Bag of Words model, but in essence it is a model which represents a text by the words in it, disregarding grammar or word order. One way to create this representation is to use a list of all words from an entire given language, and mark each word with a 0 if that word is not present in a given text, and a 1 if it is present. Another method is to count the number of times each word appears in a given document. The most popular approach is the Term Frequency-Inverse Document Frequency (TF-IDF) technique.
The technique uses the following equation, where the term frequency for the occurrence of term t in document d would be calculated as
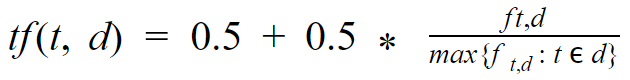
The inverse document frequency for the same document is
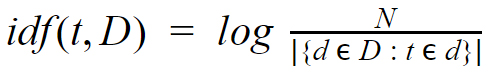
Where N is the total number of documents and D is the number of documents which contain the term t .
We calculate the TF-IDF by multiplying the results of the above two equations.
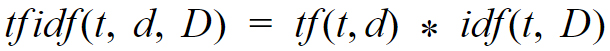
The resulting statistic represents the importance of a word to the document.
Deep Learning
Deep Learning is used to describe machine learning algorithms which represent artificial neural networks with many layers, similar to the human brain’s neural network. Deep Learning architectures are perfect for text classification problems since they are able to learn categorization incrementally through their vast hidden layer network. Our model used a Deep Convolutional Neural Network to classify texts.
Why use a Convolutional Neural Network (CNN)?
Although Convolutional Neural Networks have been traditionally been used for image classification, they are also useful for other data analysis tasks. The convolutional layers in a CNN are adept at detecting patterns, and the network provides strong validation accuracy with high consistency throughout numerous datasets. Even without large training data sets, CNNs provide higher validation accuracy and lower training time than both Recurrent Neural Networks and Hierarchical Attention Networks.
TensorFlow
 TensorFlow is a Python deep learning framework, similar to Keras, PyTorch, Theano and MXNet. We built our model using TensorFlow because of its API integrations that allowed us to quickly build at scale deep learning architecture. TensorFlow is versatile, can be run on numerous platforms, and supports a wide range of languages. The TensorFlow TensorBoard also provided an extremely useful visual and graphical monitor for the model, which aided the team with debugging.
TensorFlow is a Python deep learning framework, similar to Keras, PyTorch, Theano and MXNet. We built our model using TensorFlow because of its API integrations that allowed us to quickly build at scale deep learning architecture. TensorFlow is versatile, can be run on numerous platforms, and supports a wide range of languages. The TensorFlow TensorBoard also provided an extremely useful visual and graphical monitor for the model, which aided the team with debugging.
# Train the model
def main_train_DCNN(vocab_size, num_labels, batch_size, x_train, y_train):
model = Sequential()
model.add(Dense(512, input_shape=(vocab_size,)))
model.add(Activation('relu'))
model.add(Dropout(0.1))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.1))
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=30, verbose=1, validation_split=0.1)
# Creates an HDF5 file ‘my_model.h5’
model.save(mdl_name)
return model
Adam optimizer
To optimize our model, the team used the Adam optimization algorithm. Adaptive Moment Estimation is an algorithm which has been known to work well for a wide range of applications. It allows for quick and effective optimization using oscillation damping methods of both RMSProp and Momentum optimization.
Inference
In machine learning, inference refers to the process of making predictions by inputting unlabeled data into a previously trained model. Inference tests the trained model, and is the final step in developing an accurate text classification algorithm. After training our algorithm and fine-tuning it using the Adam optimizer, our model reached an inference accuracy of 93%.
What’s most exciting about our model?
With the launch of our robust text classification model, our team was able to automate the entire process of picking relevant client-based articles and tagging them under their respective categories, saving 80% of our analysts’ time.
Scalability
This NLP solution is easily scalable to millions of articles, as it allows quick computations for massive datasets. Data which would have once taken weeks to analyze and find insights, can now be processed in a few days.
Real-time analysis
Our model makes it easy for analysts to get insights of real time statistics for a customer. Our smart dashboard provides graphical representations of product’s share of voice.
Consistent criteria
Manual text classification often results in human error from distraction, fatigue, or inconsistent criteria. Our machine learning model eliminates potential for this error, and creates a centralized and accurate way to categorize texts.